第一篇文章里,我们已经把 LLM 的基本概念摆了一遍:token、prompt、上下文窗口、工具调用,大概都知道是什么了。
但那些概念放到真实产品里,其实还差一层。
你在聊天框里打一句话:
帮我解释一下什么是 LLM API。
屏幕上很快冒出一段回答。这个体验太顺了,顺到容易让人以为:用户的话就是直接丢给模型,模型再直接把答案吐回来。
程序里不是这么看的。
程序里看到的是一次请求。它要决定:这句话要不要加规则?要不要带上前面的聊天记录?要不要限制输出长度?模型返回的是直接展示,还是先转成 JSON?如果模型说要查订单,谁真的去查?
这篇不讲 GPU,也不讲张量计算。
我只想把聊天框背后那条使用链路拆开:一个用户问题,是怎么一步步变成一次 LLM API 调用,又怎么回到用户面前的。
01 |最小 API 调用
先从最小的形态看。
这里只有一个用户提示词,没有系统规则,没有历史对话,也没有工具。
import OpenAI from "openai";
const client = new OpenAI();
const response = await client.responses.create({
model: "gpt-5.2",
input: "用一句话解释什么是 LLM API。",
});
console.log(response.output_text);
这段代码做了三件事。
创建一个 client,指定一个 model,把 input 发出去。
response.output_text 是 SDK 帮你取出来的文本结果。它适合最简单的场景:问一句,回一句,直接展示。
这里的 SDK 可以先理解成官方给开发者准备好的调用工具。它不是模型,只是把 HTTP 请求、鉴权、参数格式、返回解析这些杂活包起来。
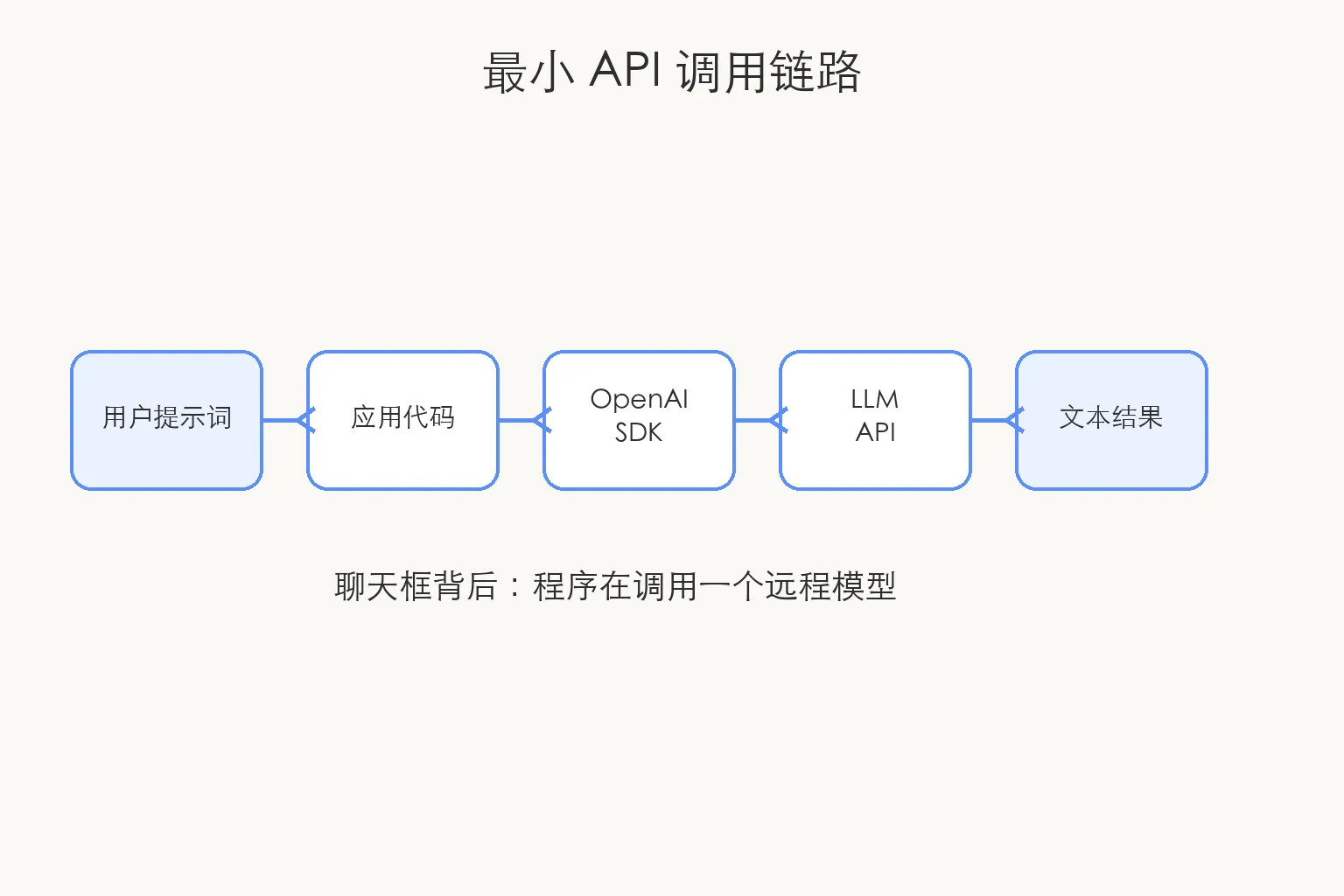
如果把聊天框剥掉,最小的 LLM 使用方式就是这样:
一个用户提示词,经过应用代码,被发到模型服务,再拿回一段文本。
这已经不是“和一个网页聊天”了。
这是程序在调用一个远程模型。
02 |系统提示词
最小调用能跑,但还不像一个产品。
假设你在做一个电商客服助手,用户输入:
帮我查一下订单 12345 到哪了?
如果只把这句话发给模型,模型可能会很努力地“扮演客服”,甚至编出一个听起来合理的物流状态。
这时候程序要加一层规则。
const response = await client.responses.create({
model: "gpt-5.2",
instructions:
"你是一个电商客服助手。回答必须简短。没有订单数据时,不要编造物流状态。",
input: "帮我查一下订单 12345 到哪了?",
});
input 是用户这次说的话。
instructions 更像应用提前写好的工作守则:你是谁,要怎么回答,哪些事情不能做。
这个地方很像一个客服系统给新人递了一张纸:
回答要短。没有查到订单数据,就说查不到。别现场编。
模型不一定真的“懂规矩”,但它会被这段规则影响。
这也解释了为什么同一个模型可以出现在很多产品里。放进客服规则里,它像客服;放进代码审查规则里,它像代码助手;放进写作规则里,它像写作搭档。
不过这里别想得太神。
系统提示词只是约束模型回答的文字,不是门禁系统。订单权限、敏感信息、付款确认,这些都不能只靠一句 prompt 兜底。
03 |历史上下文
聊天产品最容易制造一个错觉:模型记住你了。
你说:
我叫 mevin。
它回:
好的,我记下了。
你再问:
我叫什么?
它答得出来,看起来像记忆。
工程里通常没这么玄。
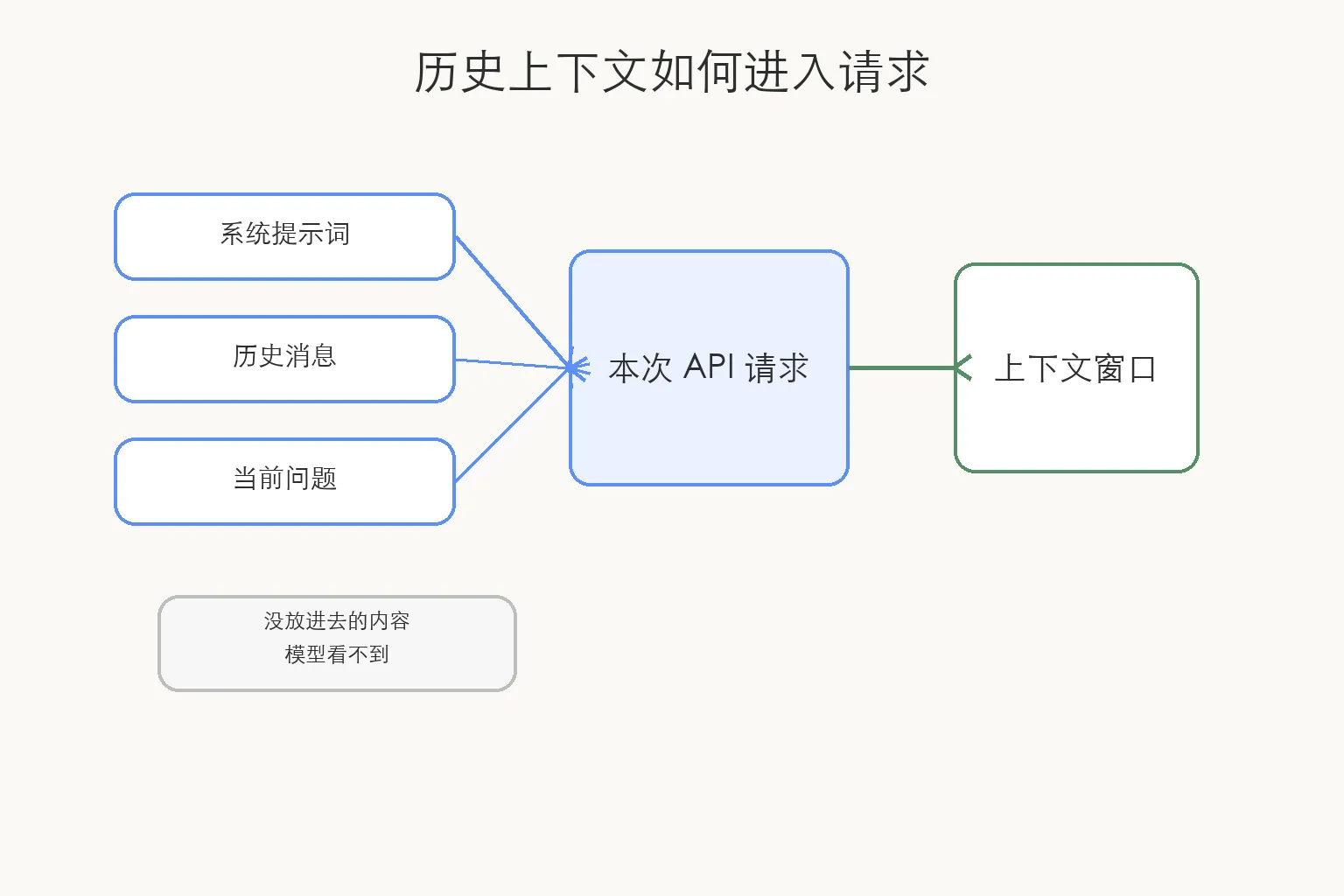
程序会把前面的几轮对话重新放进这次请求里。
const response = await client.responses.create({
model: "gpt-5.2",
input: [
{ role: "user", content: "我叫 mevin。" },
{ role: "assistant", content: "好的,我记下了。" },
{ role: "user", content: "我叫什么?" },
],
});
这段数组才是重点。
模型这次能答出来,不是因为它在某个地方永久记住了 mevin,而是因为“我叫 mevin”这句话又被放回了请求里。
第一篇讲过 context window,上下文窗口。
它不是记忆容量,更像一次考试时桌面能摊开的参考资料。桌面上有名字,它就能参考;桌面上没有,它就只能猜。
真实产品里,历史不会无限塞。
最近几轮可以直接带上,更早的内容可能被压缩成摘要,也可能存在数据库里,需要时再检索回来。很多所谓“长期记忆”,其实是应用把信息存起来,再挑合适的时候塞回上下文。
这件事没有“模型记住我”那么浪漫。
但它更接近你真正要理解的使用链路。
04 |请求参数
到这里,请求里已经有三样东西:用户提示词、系统提示词、历史上下文。
但一次 API 调用通常还会带参数。
这些参数不是主角,但它们决定这次模型怎么工作。
model 决定调用哪个模型。
temperature 决定回答更稳,还是更发散。抽取订单号、写 SQL 这类任务通常希望稳一点;想标题、想角度时可以放开一点。
max_output_tokens 限制输出长度。
stream 决定要不要边生成边返回。你在聊天框里看到文字一段段冒出来,背后通常就有流式输出。
还有 tools 和 text.format / schema,后面会讲。
这些字段放在一起,其实是在给模型划工作范围:
- 找谁回答
- 看哪些内容
- 回答多长
- 能不能用工具
- 结果要不要按固定结构回来
聊天框把这些决定藏起来了。
API 调用把它们摊在开发者面前。
05 |模型返回值
请求发出去,模型会返回结果。
最简单的时候,应用直接取 response.output_text,把文本放回聊天框。
但只要应用稍微复杂一点,返回值就不只是“一段可以展示的话”。
它可能是一段流式文本。也可能是一个符合 schema 的 JSON。也可能是一个工具调用请求。还有可能是错误信息。
这会影响程序下一步做什么。
普通聊天,展示就行。
客服系统,要保存进会话记录。
信息抽取,要解析字段再写入数据库。
工具调用,要先执行工具,再把结果交回模型。
失败了,还要重试、降级,或者告诉用户稍后再试。
这里有一个分叉:
如果返回结果是给人看的,文本就够了。
如果返回结果要继续交给程序,文本就开始不够用了。
这就引出结构化输出。
06 |结构化输出
用户说:
明天下午三点提醒我开会。
模型回:
好的,我会提醒你明天下午三点开会。
人能看懂。
程序不好用。
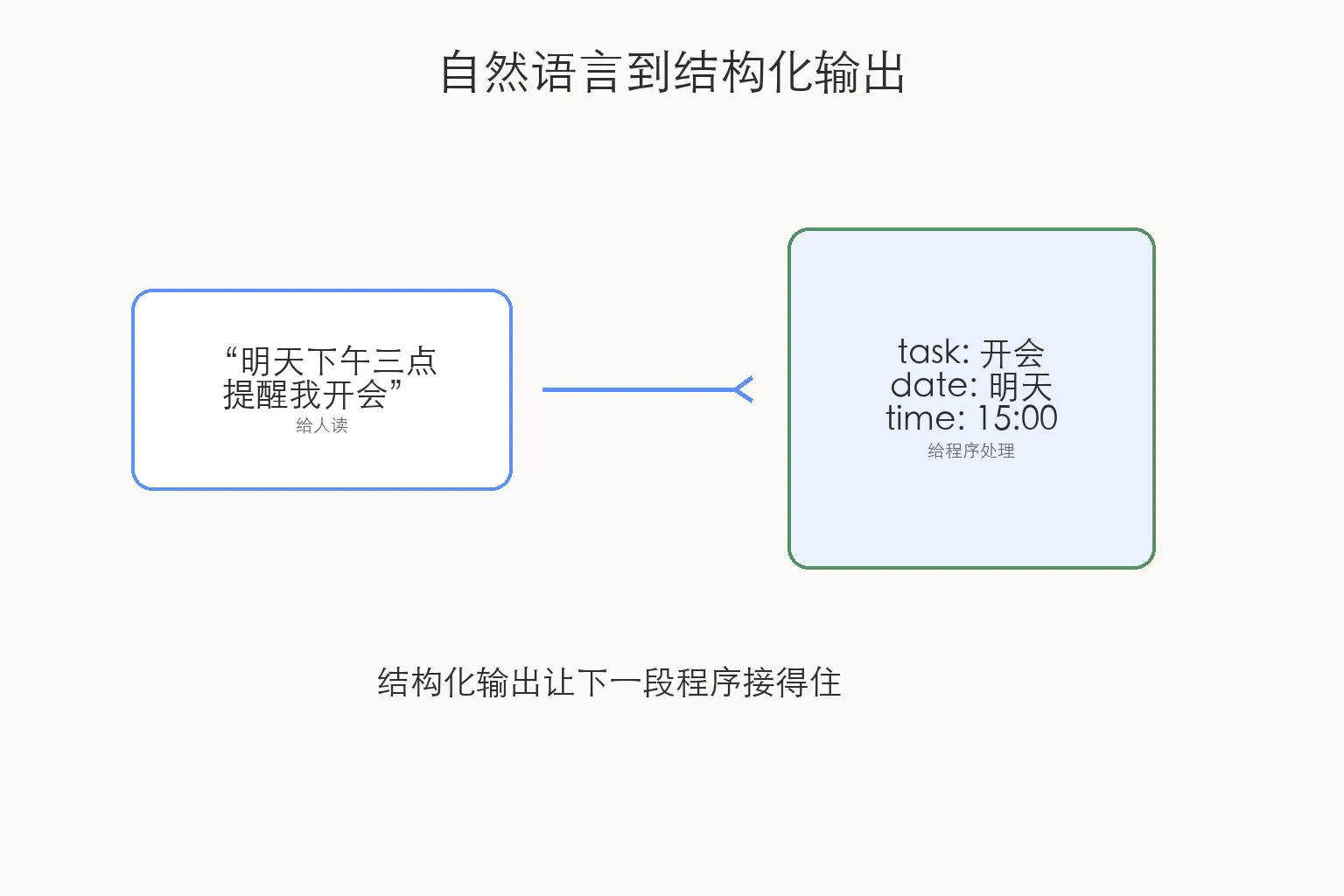
提醒系统真正需要的是更明确的字段:任务是什么,日期是哪天,时间几点。
{
"task": "开会",
"date": "明天",
"time": "15:00"
}
结构化输出解决的就是这个接力问题。
它不是为了让答案看起来更技术,而是为了让下一段程序能接得住。
日历应用要日期和时间。工单系统要分类和优先级。订单系统要订单号和查询类型。
自然语言适合给人读。
JSON / schema 适合给程序继续跑。
但结构正确,不代表内容可信。
模型可能输出一个格式完全正确、但日期解析错了的 JSON。程序还是要校验日期、权限、订单号、业务状态。
结构化输出解决的是“怎么接住结果”,不是“结果一定对”。
07 |工具调用
结构化输出解决了“结果怎么交给程序”。
工具调用解决的是另一个问题:模型什么时候需要外部系统帮忙。
用户问:
帮我查一下订单 12345 到哪了。
这不是一个纯文本问题。
模型就算文笔再好,也不能凭空知道订单状态。它需要订单系统。
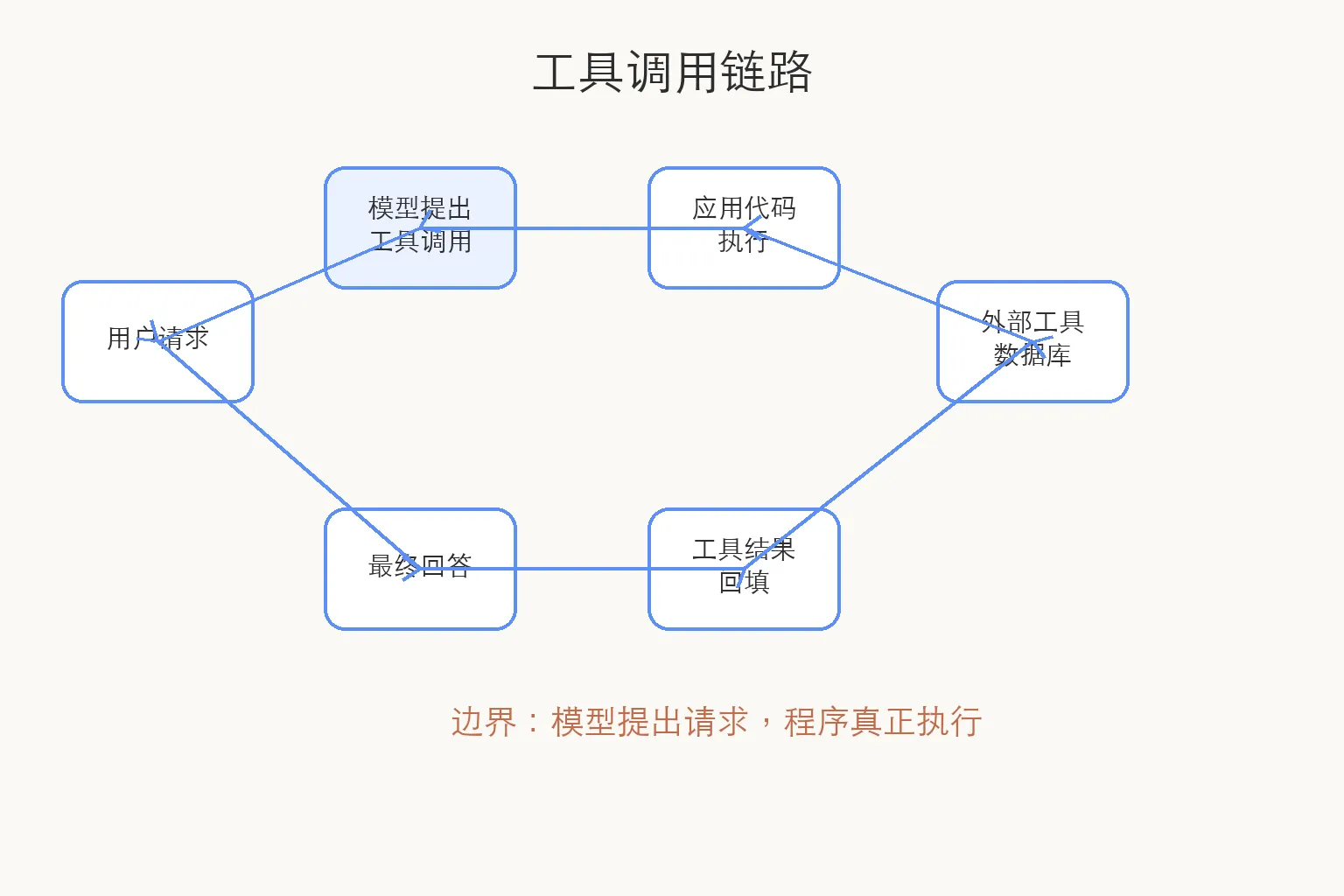
更真实的链路是:
用户:帮我查一下订单 12345 到哪了
模型:需要调用 get_order_status(order_id: "12345")
程序:执行订单查询
程序:把查询结果交回模型
模型:把结果组织成用户能读懂的话
工具调用里,模型负责提出动作:要用哪个工具,参数是什么。
程序负责执行动作:真的去查数据库、调 API、跑代码,或者拒绝执行。
这个边界一定要分清。
模型不是自己拥有外部世界的遥控器。开发者只是允许它在某些条件下“请求”工具。
查天气、查订单这类动作可以比较自动。
发邮件、付款、删文件,就不能这么随便。程序应该加权限、确认、日志,必要时让人点头。
所以工具调用不是魔法。
它只是把模型的语言判断,接到程序能执行的动作上。
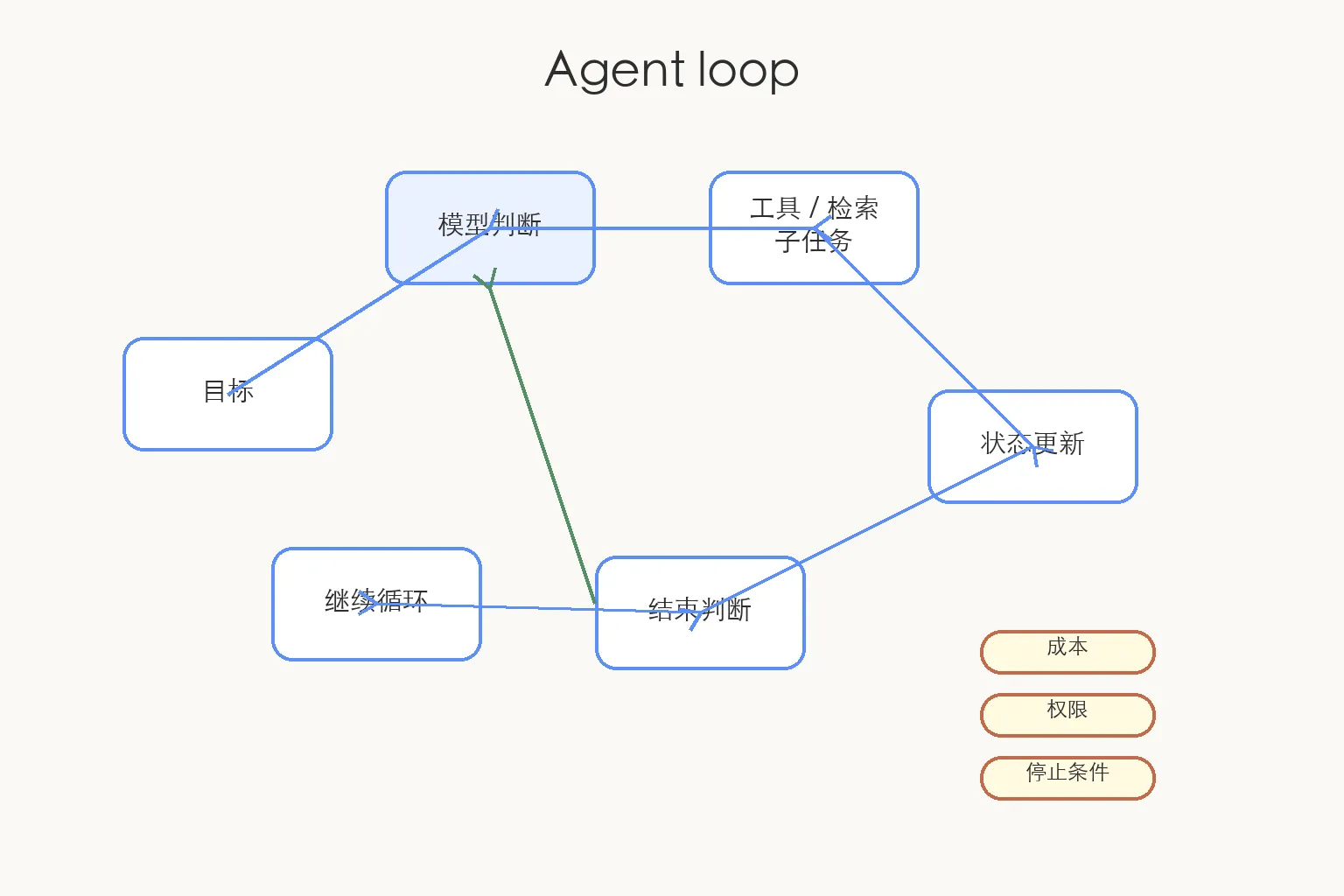
08 |Agent 循环
工具调用是一轮。
Agent 是多轮。
普通调用像这样:问一句,答一句。
工具调用多了一步:模型判断要不要用工具,程序执行工具,再把结果交回模型。
Agent 会把这个过程反复跑。
比如你让它“整理这份资料,并生成一个表格”。它可能会:
读取文件
→ 摘要内容
→ 发现缺字段
→ 再读取另一份文件
→ 生成表格
→ 检查格式
→ 返回结果
看起来像它自己在做事。
拆开看,还是模型调用、工具执行、状态更新、结束判断这几件事。
麻烦也从这里开始。
跑一轮,有一轮成本。多一个工具,多一层权限风险。任务什么时候停,中途出错怎么追踪,哪一步需要人确认,都要设计。
Agent 不该被理解成“更聪明的聊天机器人”。
它更像一套循环程序:模型负责判断下一步,工具负责执行动作,应用负责记录状态和决定什么时候停。
MCP 可以放在旁边理解。
它不是模型,也不是 Agent 本身。它更像一套连接标准,让工具和数据源更容易接进应用。
09 |程序责任
现在可以把这条链路压成一句话:
LLM 应用不是“用户把话发给模型”,而是应用把用户输入包装成一次可控请求,再决定怎么处理模型返回的东西。
最小调用里,只有用户提示词。
加上系统提示词,应用开始给模型设规则。
加上历史上下文,多轮对话才成立。
加上请求参数,模型这次怎么回答开始有边界。
拿到返回值之后,应用要判断它是直接展示、保存、解析,还是继续处理。
结构化输出让结果能进入程序逻辑。
工具调用让模型可以请求外部动作。
Agent 循环把这些动作串成多轮任务。
这里面最容易被忽略的是责任边界。
模型可以生成、判断、组织语言。
但保存上下文、校验输出、执行工具、控制权限、记录日志、处理失败,这些都是应用的事。
用户看到的是聊天框。
开发者真正要设计的,是聊天框背后的这条程序链路。